e-Stat🤝R
Tokyo.R #108
2023-09-02
e-Statとは❓
- 日本の政府統計ポータルサイト
- 多くの統計データを検索・閲覧・取得可能👍
画像出典:e-Stat
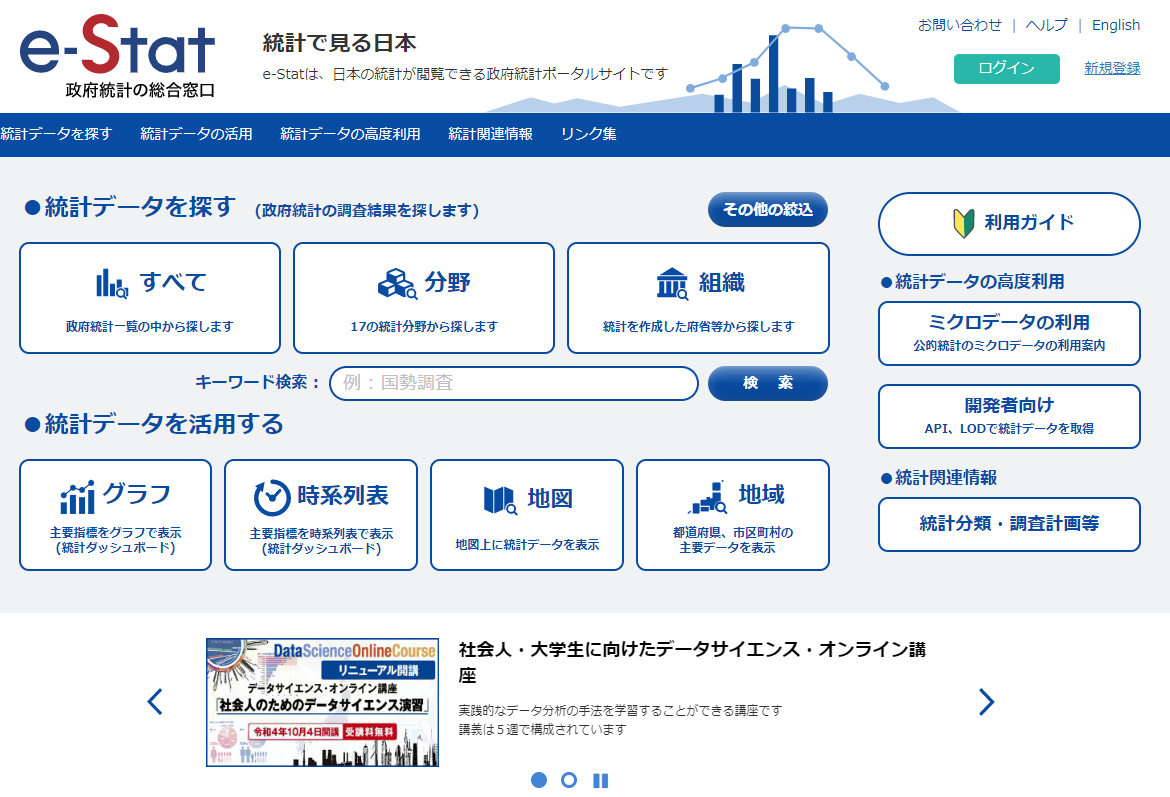
e-Statの使い方📌
1. データベースを検索🔎
画像出典:e-Stat
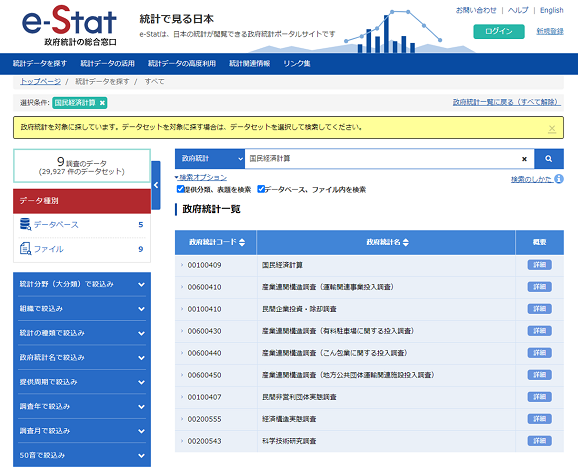
e-Statの使い方📌
2. データベースを選択👆
画像出典:e-Stat
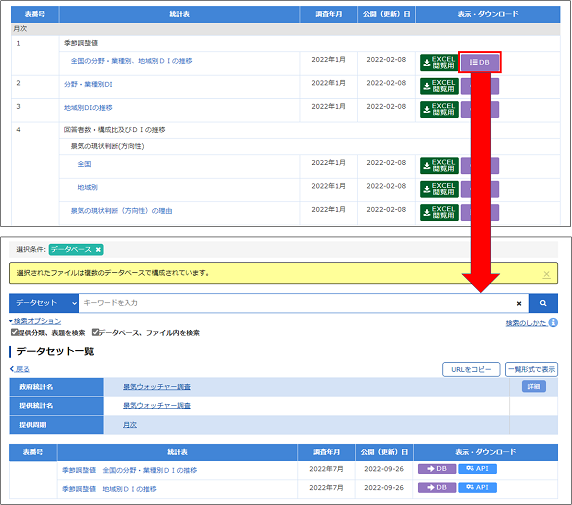
e-Statの使い方📌
2. データベースを選択👆
画像出典:e-Stat
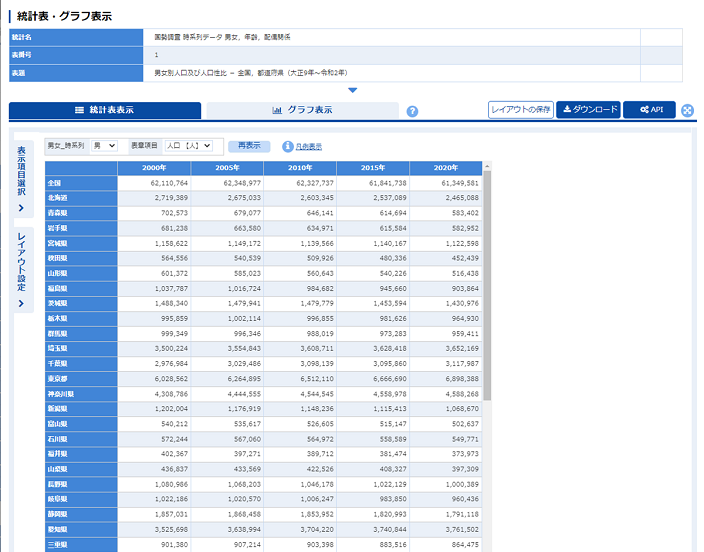
e-Statの使い方📌
3. データ項目を選択✅
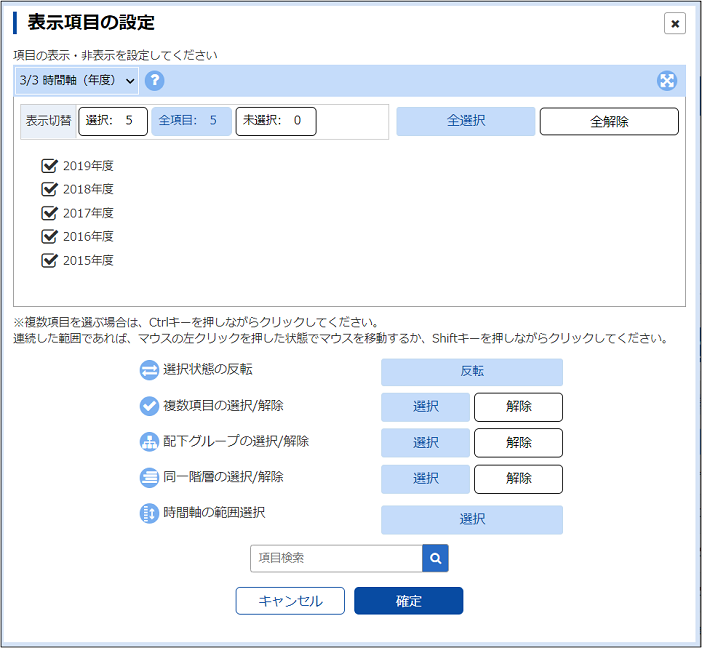
画像出典:e-Stat
e-Statの使い方📌
4. データをダウンロード💾
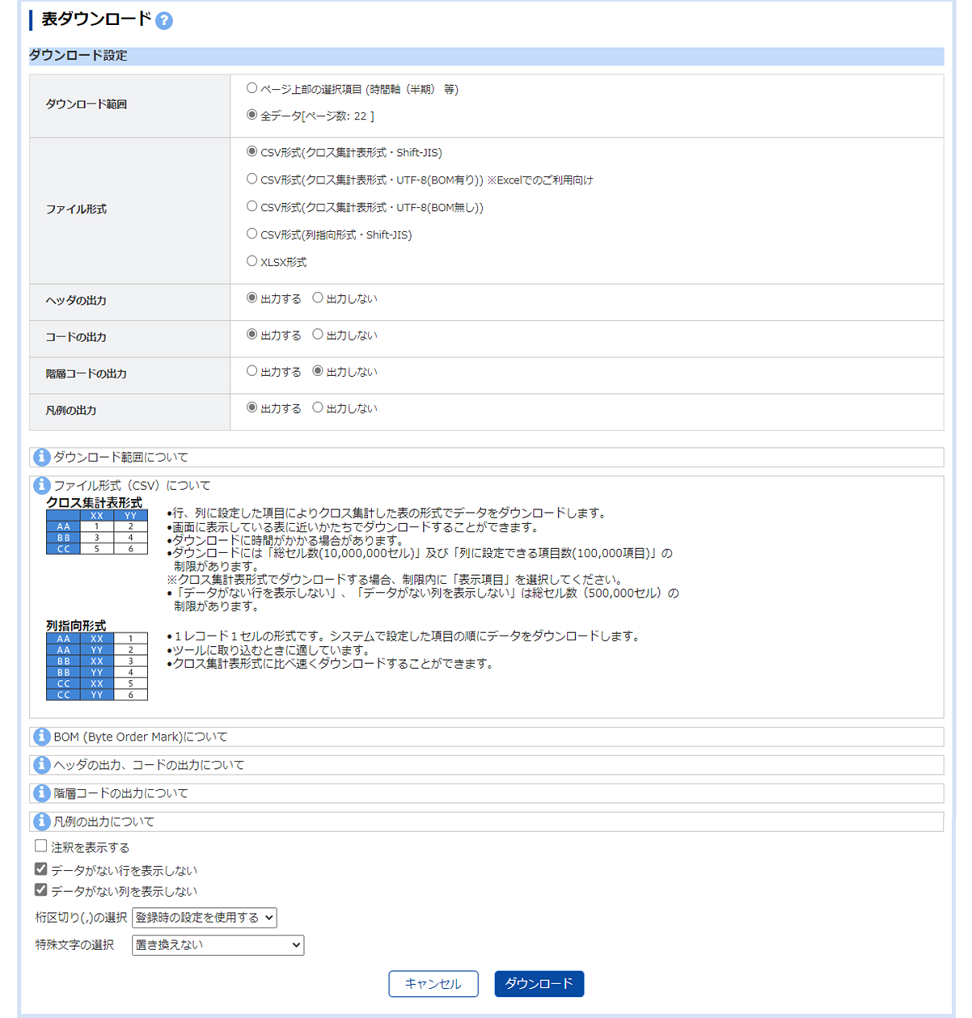
画像出典:e-Stat
Enjoy🍫
余談:2月はチョコレート消費が増えることがわかった!
Code
chocolate |>
mutate(世帯区分_name = 世帯区分_name |>
str_remove("(2000年~)$") |>
as_factor(),
金額 = parse_number(金額)) |>
ggplot(aes(月次_name, 金額,
fill = 世帯区分_name)) +
geom_col(position = "dodge") +
scale_x_discrete(NULL) +
scale_y_continuous("1世帯あたり金額[円]",
labels = scales::label_comma()) +
scale_fill_brewer("世帯区分",
palette = "Paired") +
facet_wrap(~ 品目分類_name)